Thursday, June 30, 2011
Monday, June 27, 2011
DSP Trick: Magnitude Estimator
To compute the approximate absolute magnitude of a vector given the real and imaginary parts:
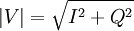
use the alpha max plus beta min algorithm. The approximation is expressed as:

For closest approximation, the use
 and
and

giving a maximum error of 3.96%.
To improve accuracy at the expense of a compare operation, if Min ≤ Max/4, we use the coefficients, α = 1 and β = 0;
otherwise, if Min > Max/4, we use α = 7/8 and β = 1/2.
Division by powers of 2 can be easily done in hardware. Error comparisons for various min/max values:

use the alpha max plus beta min algorithm. The approximation is expressed as:
For closest approximation, the use
giving a maximum error of 3.96%.
To improve accuracy at the expense of a compare operation, if Min ≤ Max/4, we use the coefficients, α = 1 and β = 0;
otherwise, if Min > Max/4, we use α = 7/8 and β = 1/2.
Division by powers of 2 can be easily done in hardware. Error comparisons for various min/max values:
 |  | Largest error (%) | Mean error (%) |
|---|---|---|---|
| 1/1 | 1/2 | 11.80 | 8.68 |
| 1/1 | 1/4 | 11.61 | 0.65 |
| 1/1 | 3/8 | 6.80 | 4.01 |
| 7/8 | 7/16 | 12.5 | 4.91 |
| 15/16 | 15/32 | 6.25 | 1.88 |
| α0 | β0 | 3.96 | 1.30 |
Sources:
- http://www.dspguru.com/book/export/html/62
- http://en.wikipedia.org/wiki/Alpha_max_plus_beta_min_algorithm
- http://www.eetimes.com/design/embedded/4007218/Digital-Signal-Processing-Tricks--High-speed-vector-magnitude-approximation/
- Mark Allie and Richard Lyons, "A Root of Less Evil," IEEE Signal Processing Magazine, March 2005, pp. 93-96.
Wednesday, June 22, 2011


Monday, June 20, 2011
Install GNOME 3 on Ubuntu 11.04
Open the terminal and run the following commands
sudo add-apt-repository ppa:gnome3-team/gnome3 sudo apt-get update sudo apt-get dist-upgrade sudo apt-get install gnome-shell
Thursday, June 16, 2011
Syntax Highlighting Added
Thanks to this post, I now use syntax highlighting:
http://practician.blogspot.com/2010/07/color-my-world-syntax-highlighter.html
Original code for WordPress from Alex Gorbatchev is here and description is here.
Hope you like it.
http://practician.blogspot.com/2010/07/color-my-world-syntax-highlighter.html
Original code for WordPress from Alex Gorbatchev is here and description is here.
Hope you like it.
Friday, June 10, 2011
Wednesday, June 1, 2011
Paper Review: Histograms of Oriented Gradients for Human Detection. Navneet Dalal and Bill Triggs
Thanks to Joel Andres Granados, PhD student in the IT University of Copenhagen. You saved me some effort! http://joelgranados.wordpress.com/2011/05/12/paper-histograms-of-oriented-gradients-for-human-detection/
Approach:
Approach:
- First you calculate the gradients. They tested various ways of doing this and concluded that a simple [-1,0,1] filter was best. After this calculation you will have a direction and a magnitude for each pixel.
- Divide the angle of direction in bins (Notice that you can divide 180 or 360 degrees). This is just a way to gather gradient directions into bins. A bin can be all the angles from 0 to 30 degrees.
- Divide the image in cells. Each pixel in the cell adds to a histogram of orientations based on the angle division in 2. Two really cool things to note here:
- You can avoid aliasing by interpolating votes between neighboring bins
- The magnitude of the gradient controls the way the vote is counted in the histogram
- Note that each cell is a histogram that contains the “amount” of all gradient directions in that cell.
- Create a way to group adjacent cell histograms and call it a block. For each block (group of cells) you will “normalize” it. Papers suggests something like v/sqrt(|v|^2 + e^2). Note that V is the vector representing the adjacent cell histograms of the block. Further not that || is the L-2 norm of the vector.
- Now move through the image in block steps. Each block you create is to be “normalized”. The way you move through the image allows for cells to be in more than one block (Though this is not necessary).
- For each block in the image you will get a “normalized” vector. All these vectors placed one after another is the HOG.
Comments:
- Awesome idea: The used 1239 pedestrian images. The SVM was trained with the 1239 originals and the left-right reflections. This is so cool on so many levels. Of course!! the pedestrian is still a pedestrian in the reflection image. And this little trick give double the information to the SVM with no additional storage overhead.
- They created negative training images from a data base of images which did not contain any pedestrians. Basically randomly sampled those non-pedestrian images and created the negative training set. They ran the non-pedestrian images on the resulting classifier in look for false-positives and then added these false-positives to the training set.
- A word on scale: To make detection happen they had to move a detection window through the image and run the classifier on each ROI. They did this for various scales of the image. We might not have to be so strict with this as all the flowers are going to be within a small range from the camera. Whereas pedestrians can be very close or very far from the camera. The point is that the pedestrian range is much larger.
- A margin was left in the training images. of 4 pixels.
Subscribe to:
Comments (Atom)